





Ciao a tutti, nell’articolo di oggi vi voglio parlare di un progetto che ho seguito per centralizzare e monitorare i log di 300 applicazioni web in tempo reale.
Contesto
L’azienda per la quale lavoravo aveva al suo attivo circa 300 applicazioni web – su 6 diversi webserver – sia ad uso interno sia vendute come servizio. Il team di sviluppo era composto da 3 sviluppatori fissi, un responsabile che faceva da Project Manager e un consulente, dedicato allo sviluppo quando presente.
Le applicazioni erano molte, il team non era enorme e bisognava trovare un modo per cercare di “anticipare” le richieste di bug che ci venivano inoltrate: il giro era sempre lo stesso, l’utente scopriva il bug, non avvisava nessuno e quando poi diventava necessario risolverlo apriva una segnalazione al nostro ufficio con carattere di urgenza🚨
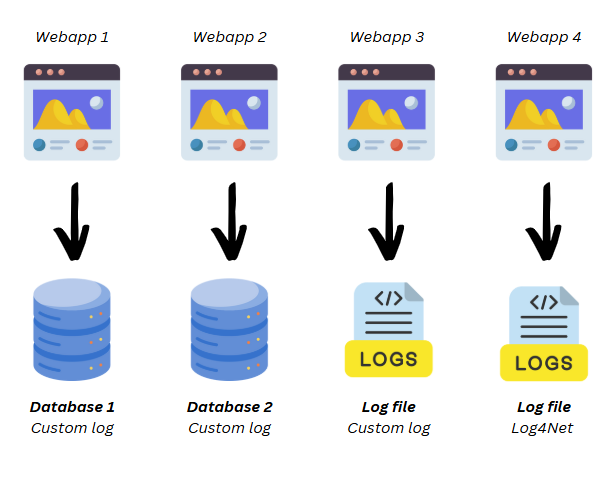
Oltre a questo non esisteva uno standard su come andare a produrre dei log e non era neanche la regola. Molti log erano salvati su file system (scritti in modo custom o tramite libreria come Log4Net), altri erano salvati sui database dedicati delle applicazioni (ogni applicazione aveva le “sue” tabelle di log, simili ma non uguali).
Il problema
I problemi da risolvere erano due:
- Definire uno standard su come andare a generare i log
- Trovare un modo per poter monitorare tutti i log nel loro insieme
Libreria di log standard
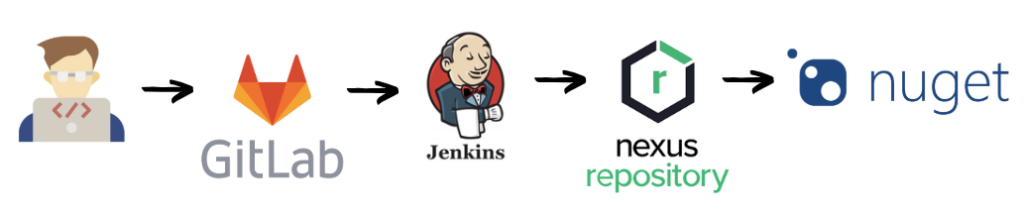
Come prima cosa ho voluto uniformare e standardizzare il modo con il quale andavamo a tracciare i log applicativi, per farlo ho creato una libreria custom da includere nei vari progetti (sviluppata in .NET Standard poiché il parco applicazioni contemplava sia .NET Framework che .NET Core).
La libreria era rilasciata in automatico tramite Jenkins sul sistema Nexus Sonatype (un repository Nuget che avevo configurato qualche anno prima per poter migliorare la gestione delle librerie). In questo modo la mia libreria di log era facilmente installabile sui progetti ed eventuali aggiornamenti sarebbero stati segnalati nei vari progetti.
La libreria aveva un suo meccanismo interno di migration e installava sul database applicativo 4 tabelle “standard” di log (in caso di problemi scriveva su file):
- Una tabella per i log generici
- Una tabella per tracciare solo le chiamate API (interne o verso sistemi terzi)
- Una tabella dedicata ai log del frontend
- Una tabella per gestire log raggruppati e avere delle metriche più analitiche
Da questo momento in poi, ogni volta che aprivamo un progetto nuovo andavamo ad installare la libreria e sostituire tutti i vecchi metodi di log con i metodi nuovi. Nel giro di qualche mese i database con i nuovi log diventarono circa 50.
ELK (Elasticsearch – Kibana – Logstash)
A questo punto dovevo pensare a quale strumento utilizzare per monitorare e centralizzare i log, per farlo ho scelto ELK, uno stack composto da Elasticsearch (database), Kibana (dashboard) e LogStash (per recuperare i log).
Lo stack è gratuito ed open source (ad esclusione di alcune funzionalità più avanzate che sono a pagamento) ma per quello che l’ho utilizzato mi è sempre bastato.
Il principio di funzionamento è molto semplice: Logstash recupera i log dai vari database, li salva in Elasticsearch e successivamente è possibile costruire delle dashboard di visualizzazione tramite Kibana.
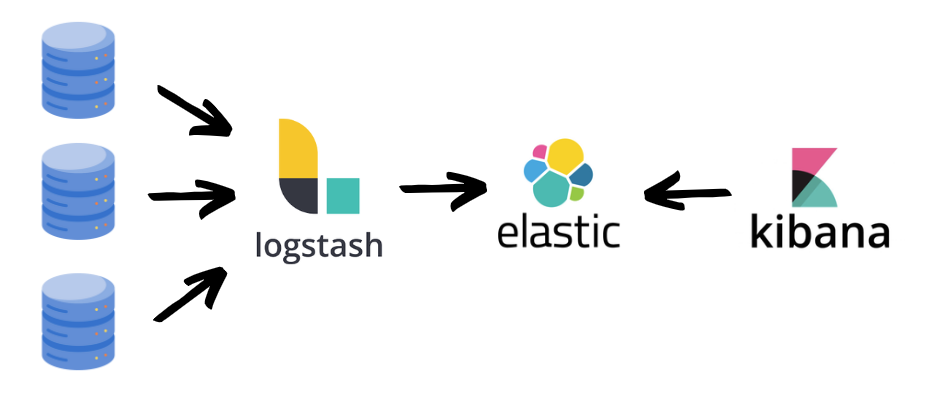
In realtà Logstash nasce con l’idea di leggere i log in formati differenti, uniformarli e salvarli. Questo passaggio a me non interessava poiché avevo già risolto il problema con la mia libreria di log.
Configurazione ELK
Come primo passo ho installato – su un server aziendale – lo stack ELK, seguendo la guida ufficiale. Subito dopo ho generato i certificati per la connessione https tra i 3 elementi, necessario per alcune configurazioni di Logstash.
Il passo successivo è stata la configurazione degli indici e datastream: sono dove andranno salvati i log, in questo caso ho configurato 4 datastream differenti, uno per ogni tabella di log ( a prescindere dal database dal quale arrivava ).
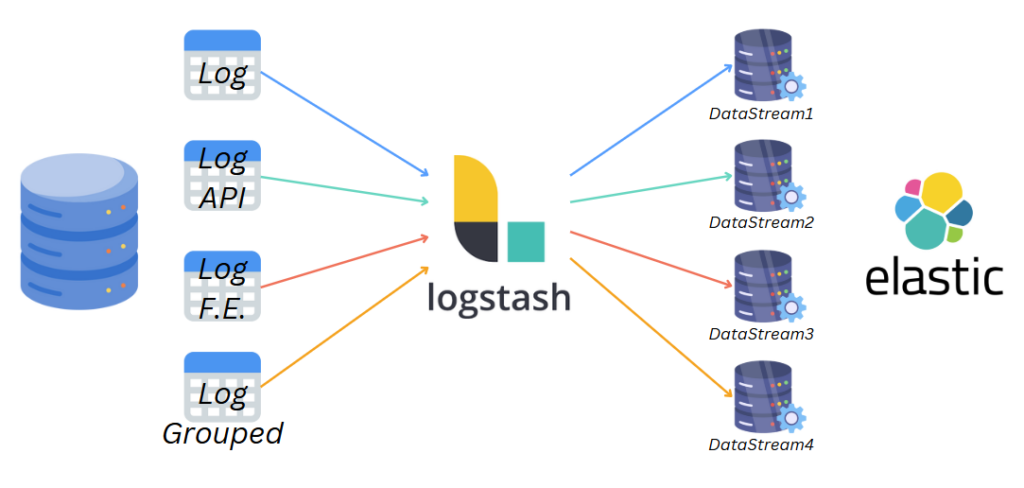
Configurazione Logstash e generazione automatica pipeline
Logstash importa i dati leggendo delle pipeline nella sua cartella di configurazione.
Problema
Non volevo creare manualmente una pipeline ogni volta che un nuovo database con i log nasceva, volevo un qualcosa di automatico che creasse (o eliminasse) le pipeline.
Il passo successivo è stato quello di sviluppare un servizio windows che si occupasse di:
- Leggere tutti i database che contenevano le tabelle dei log standard (i db server coinvolti erano 4)
- Centralizzare le informazioni in un suo database, aggiungendo i nuovi database all’elenco e disattivando quelli che erano stati archiviati ( * )
- Creare in automatico le pipeline per i nuovi database
- Eliminare le pipeline che si riferivano a database archiviati o eliminati
( * ) I nuovi database erano censiti in una tabella, manualmente configuravo alcuni parametri quali nome della pipeline e tag da aggiungere ai log, infinite impostavo un flag per “attivare” la creazione della pipeline. In questo modo evitavo che database di test o temporanei finissero in ELK.
Le pipeline erano generate in automatico a partire da un template e contenevano le query da eseguire sulle 4 tabelle di log, la destinazione dei dati in ELK, la frequenza di aggiornamento ed il campo identity da controllare per evitare di importare log doppi.
Una volta concluso lo sviluppo di questo servizio le pipeline si creavano ed eliminavano in modo automatico ed ero pronto per l’ultimo passaggio.
Configurazione Kibana
A questo punto della nostra storia abbiamo le pipeline che si generano in automatico e Logstash che recupera i log e li salva su Elasticsearch. Ci manca solo di visualizzare i dati e per farlo utilizzeremo Kibana.
Kibana è anche lo strumento utilizzato per poter gestire lo stack, visualizzare gli indici e gestire i datastream, tutti passaggi già visti prima. Per questo mio progetto ho configurato una dashboard dedicata con degli indicatori di analisi su:
- Lista di tutte le API andate in errore
- Applicazioni che stanno generando più errori (ERROR / EXCEPTION) negli ultimi X minuti (filtro impostato a livello di dashboard)
- Applicazioni più utilizzate
- Applicazioni meno utilizzate (utile per capire quali applicazioni dismettere)
- Lista di tutti i log di errore
Conclusioni
In questo articolo abbiamo visto come ho gestito il problema di dover centralizzare e monitorare i log delle 300 applicazioni. In principio era il caos, ora invece è tutto ordinato e nel momento in cui sto scrivendo questo articolo più di un centinaio di applicazioni convogliano i log in ELK 🙂
Nelle prime settimane abbiamo rilevato un’enorme quantità di errori nelle applicazioni più utilizzate: indagando abbiamo scoperto che le applicazioni andavano in errore ma le persone trovavano “workaround” per bypassarli, semplicemente perché aprire una segnalazione era troppo oneroso 😞
Tutto questo lavoro è servito a qualcosa? La mia risposta è si, riusciamo a tracciare molti errori prima che questi divengano bloccanti e migliorare l’esperienza utente in molti processi.
Il prossimo passo sarà quello di predisporre un monitor d’ufficio (o meglio ancora una TV) per poter controllare sempre la dashboard, in tempo reale!
Grazie per la lettura, al prossimo articolo!